VALIDATA SENSE.AI
Validata Sense.ai is an award-winning, no-code, all-in-one continuous quality engineering automation platform for all your testing needs: core banking, interfaces and payments testing.
With AI, Robotic Process Automation (RPA), and predictive analytics at its core, ValidataSense.ai delivers unparalleled efficiency, reliability, and speed enabling teams to expand automation beyond just test execution and paving the way to Autonomous Testing.
We are here to help you rid the world of bugs, reduce operating costs, become 40x more productive with increased quality at speed.



Traditional QA is not working
Software testing teams remain the #1 bottleneck in the process. If you have a fast-paced DevOps teams but your testing is slow, there is no way you achieve the required delivery speed.
According to Omdia (ex- Ovum), traditional approaches and self-made automation frameworks:
- Lack of a Test Analytics model and are fundamentally about testing the low-level code
- Tend to automate the mechanical not the analytical part of testing
- They are not focused on optimizing customer experience
- Don’t scale efficiently with high coverage.
This means that when you use them in your testing projects, testing becomes more of a coding challenge rather than a testing challenge.
The more time you spend on coding, the less time you spend to uncover defects that impact user experience!
Unlike traditional approaches, Validata Sense.ai focuses on the analytical rather than the mechanical part of testing, offering a unique approach to help teams focus testing on what matters to your users and your business.
One Platform that seamlessly connects
across the ALM lifecycle
A modern, cloud-native, microservices-based, API-first architecture with a core set of game-changing features that form the foundation of the platform:
Simple n’ Easy Requirements Engineering capabilities to design, capture, trace, analyse, visualise, and manage your requirements, delivering better quality applications to market faster.
Leveraging AI it can automatically generate end-to-end test workflows covering a wider range of end-user journeys, and provide real-time suggestions on the optimal testing paths, and the ‘next best steps’ for maximum coverage.
Instant access to ‘fit for purpose’, secure and compliant data on demand, through synthetic data generation and AI-powered data masking capabilities.
It enables end-to-end visibility and transparency, with pre-built analytics, enabling teams assess project health and status, predict delivery, focus on quality goals and align QA & testing schedules with continuous delivery schedules.
End-to-end visibility into process efficiency and gain insights into the cost of quality to reduce delays, minimize unnecessary costs, and enhance overall operational effectiveness.
Leveraging AI and machine learning it can predict, identify, and resolve defects in real time. By automating root cause analysis and defect classification, it minimizes costs, enhances collaboration, and accelerates development—ensuring higher software quality, stability, and optimized resource allocation.

- all in one!
Model-Driven, No-code: Create the ‘Digital Twin’ of your application
It is a model-driven, no-code platform that radically accelerates the delivery of digital testing powered by industry-leading model-based test automation. This scriptless approach delivers 90%+ test automation rates while significantly reducing maintenance costs.
It takes all the required input from the production environment, the application under test (AUT) and the database under test, and uses “specific modeling” principles to build the application knowledge within the platform.
Whenever there is a change in your application the model gets updated automatically, and the changes are automatically applied to all impacted assets.
The continuous learning and self-healing features, ensure that your testing is not only more efficient but also continuously improving. It also helps you discover the best shortest path to discovering issues faster shifting testing left.

Test Smarter... Τest Faster with AI
The core of Validata Sense.ai is our AI engine, Annie, comprised of AI and advanced machine learning algorithms, as well as a learning engine that uses Particle Swarm Optimisation (PSO) and Artificial Bee Colony (ABC) algorithms which are part of our computational intelligence technology.
Annie acts as the ‘central nervous system’ with continuous learning and self-healing features, ensuring that your testing is not only more efficient, but also continuously improving. It finds the optimal tests to maximise business coverage and defect detection at a given time, resources and budget constraints, and optimizes test execution ensuring high risk coverage in less time, with less resources and less testing!

Integrate Continuous Quality Throughout your CI/CD process
With seamless integration into your existing CI/CD pipelines and popular DevOps tools like Jira, Jenkins, and Microsoft Azure, test automation becomes a natural extension of your development lifecycle. And enables you to manage your continuous delivery with a consistent approach across all forms of testing.
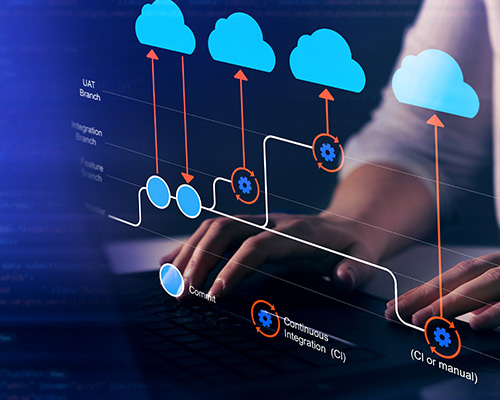
Unleashing the power of end-to-end composable test automation
Composable test automation, comprises modular building blocks encompassing groups of test steps. This approach takes reusability and agility to new heights.
Unlike traditional automation tools, ValidataSense.ai provides fully reusable end-to-end test workflows that can be run against any environment. By adopting a modular approach and leveraging building blocks of automation, testers can supercharge their testing processes, saving time, enhancing efficiency, and ensuring robust decision-making. Embracing composable test automation unlocks a new realm of possibilities, paving the way for a future where testing becomes more streamlined, adaptable, and impactful.

Quality Engineering in Agile
Validata Sense.ai offers a collaborative platform where quality engineers and developers work together, leveraging AI-driven analytics to monitor and improve software quality in real-time:
- ‘Shift Left’ testing: Unlike traditional approaches, testing begins on day one and is carried out iteratively.
- Continuous Feedback: Frequent stakeholder reviews and feedback loops ensure the product aligns with user needs and expectations.
- Utilize features like test data automation and environment management to support efficiency.
- Move beyond tracking process metrics and automation coverage by focusing on outcomes that enable faster delivery times, enhance product quality and customer satisfaction. This shift allows teams to make more informed decisions for better business outcomes.
Proven ROI
Do 24 days’ worth of testing in just 24 hours!
Τransform testing from a cost center to a profit center!
EXPLORE THE BENEFITS YOURSELF
Streamline your testing processes with the #1 AI-powered all-in-one super app
Time is of the essence, so book your demo today!

SOLUTIONS TAILORED TO EVERY NEED
Validata’s AI-powered solutions
right at your fingertips
Performance Engineering
Fine-tune your mission-critical applications with Validata Sense.ai for Performance Testing, a powerful tool designed for banks and financial services organisations of all sizes.
Run comprehensive performance testing, simulating various traffic loads to identify bottlenecks and optimise system scalability. With features like integrated ramp-up/ramp down functionality, mixed transaction testing, and monitoring capabilities, Performance Testing helps minimise costs and risks by 50% while accelerating high-quality application delivery.
By providing real-time, actionable insights and user-specific testing scenarios, this tool makes sure that your applications meet performance requirements, enhances user experience, and aligns with business objectives, giving you the necessary confidence to take your operations to the next level.
Learn MoreAPI & Web Services Testing
The API & Web Services Testing solution revolutionises API testing based on AI and machine learning, offering advanced automation for creating and maintaining test assets, without even a scrap of coding required. This way you ensure the resilience, reliability, and performance of business-critical applications by automating complex end-to-end scenarios across multiple endpoints and enabling continuous testing, covering all possible bases.
With capabilities such as automated functional and regression testing, seamless integration with various environments, and support for error testing, Validata's solution enhances API testing efficiency and accuracy, safeguarding the seamless operation of interconnected business processes within the entire digital landscape it operates in.
Learn MoreClient Statements & Contract Notes Testing (PDF Validation)
We know that struggling with pages-long PDF files of Client Statements & Contract Notes on a daily basis takes up a lot of time when done manually.
With Client Statements & Contract Notes Testing, you can automate the validation of PDF and CSV documents, ensuring accuracy in content and structure. Compare the files against core banking data, detecting mismatches in formatting, content, figures, and values that otherwise could go unnoticed. This automated approach enhances test coverage, speeds up document validation processes, and can eliminate the risk of human errors, providing reliable results for banks and financial services organisations to ensure accurate customer communications and unencumbered provision of services to end customers.
Learn MoreFunctional Testing
Accelerate your software release cycles with Validata Sense.ai for Functional Testing. Designed to streamline the testing process, this no-code, scriptless tool empowers teams to conduct end-to-end tests without the need for complex coding. By automating functional testing, Validata Sense.ai helps identify defects early in the development lifecycle, reducing errors and ensuring a smoother, faster release process. This means your team can focus on delivering high-quality applications while staying ahead of project deadlines.
Incorporating AI-driven insights and real-time monitoring, Validata Sense.ai ensures your applications meet performance standards before they reach users. The platform optimises testing times, cutting what could take months down to days. This automated solution reduces costs and allows businesses to focus on innovation and customer satisfaction. Eliminate costly errors and accelerate time-to-market with functional testing that aligns perfectly with your business needs.
Learn MoreAutomated Regression Testing
Validata Sense.ai for Regression Testing transforms how businesses maintain the integrity of their software. This AI-powered solution automates the traditionally tedious and time-consuming regression testing process, reducing the need for manual testing. With its predictive models, Validata Sense.ai detects defects early and automatically updates regression test packs with real-time business data, ensuring continuous accuracy and reliability. This reduces the risk of post-update failures, making your system more resilient with each iteration.
By dramatically reducing testing times from what could have been weeks to only hours, Validata Sense.ai’s automated regression testing streamlines workflows and optimises resources. It empowers teams to execute faster, more accurate test cycles, allowing them to focus on critical business operations. Experience smarter testing with reduced costs, faster results, and guaranteed software performance after every update.
Learn MoreMobile Testing
In today's mobile-first world, delivering seamless app performance across platforms is critical, and Validata Sense.ai for Mobile Testing makes it effortless. Its AI-powered automation ensures consistent performance on iOS, Android, and other devices by detecting bugs from an early point and resolving performance issues before they affect users. Integrated with CI/CD pipelines, Validata Sense.ai accelerates mobile app development, allowing for faster updates without sacrificing quality.
This cross-platform solution helps businesses reduce operational costs by automating repetitive tasks and streamlining workflows. With real-time analytics and early issue detection, Validata Sense.ai ensures your mobile applications perform flawlessly, keeping users engaged and satisfied. Achieve quicker time-to-market while delivering an exceptional user experience—every time.
Learn MorePayments and ISO 20022 Test Automation
Validata Sense.ai transforms your payment testing process with its AI-powered automation platform. Handling complex ISO 20022 message formats becomes now easy and effortless. By supporting all major payment schemes, such as SWIFT, SEPA, and Real-Time Payments, it ensures seamless and accurate testing of your payment flows. With faster test cycles and increased test coverage, Validata Sense.ai for Payments and ISO 20022 Test Automation helps reduce costs while maintaining the integrity of your systems.
Our end-to-end solution offers automated risk-based regression testing to ensure your system remains reliable, even during updates. By using synthetic test data generation, you can validate all message types and ensure accuracy without the manual overhead, but with frictionless onboarding and the flexibility of cloud or on-premise deployment.
Learn MoreSystems Integration Testing
Validata Sense.ai for Systems Integration Testing (SIT) empowers businesses to streamline complex testing of interconnected systems with an AI-powered, no-code platform. From cloud to on-premise environments, our platform automates end-to-end testing, ensuring smooth communication between systems and eliminating integration risks. With smart API integrations and distributed execution, you can perform compatibility testing across multiple systems, ensuring seamless functionality while saving time and reducing manual intervention.
Automatically generate synthetic test data for comprehensive coverage and perform continuous regression testing to prevent system disruptions during upgrades. With legacy and modern system compatibility testing, ensure smooth operations across your entire tech stack. Improve operational efficiency, reduce manual effort, and accelerate testing without compromising quality.
Learn MoreUAT Support / Manual Testing
Validata Sense.ai can also support manual testing execution for UAT enabling testers to perform and track manual testing processes within a structured and centralized platform. It facilitates seamless execution of user acceptance test cases by providing features like step-by-step test execution guidance, real-time result recording, and defect logging.
Additionally, it supports collaboration between testers and stakeholders by offering dashboards, reporting, and traceability to ensure that all business requirements are validated effectively. This ensures comprehensive test coverage, accurate defect tracking, and enhanced visibility, ultimately improving the quality and efficiency of the UAT process.
Learn MoreHow Validata Sense.ai is different and better
Simple, upgradeable and sustainable automation that is 20x faster compared to any other tool.
A plug-and-play SaaS platform, allowing you to start testing instantly. Skip the hassle of building frameworks and enjoy rapid deployment with zero lead time.
Demand extensive setup and framework creation, they are more complex and the learning curve is steeper delaying test automation. Specialist teams must configure from scratch, extending project timelines and adding complexity.
Validata Sensei.ai is an all-in-one platform including everything from requirements modelling to automated test case generation, data intelligence and environments provisioning, defects prevention and test analytics suitable for all types of testing.
Require additional tools for requirements, test data management, defect management, as well as additional scripting and effort to support different types of testing.
Code-free, model-based test automation enabling non-technical users and business analysts to make automation that is maintainable and resilient, without the need for programming cutting down testing headcount by 50% and eliminating the need for separate manual testers.
Require extensive coding expertise. The more time you spend on coding the less time is spent on testing!
AI-powered self-healing automation detects changes in real-time, automatically updating tests, drastically reducing maintenance costs and ensuring your testing stays up-to-date without manual intervention.
Frequent software changes may require traditional and open source tools to be manually updated, creating high maintenance overhead and adding technical debt. Continuous adjustments are needed to keep scripts running smoothly.
Automatically generates tests and data reducing the test design effort by 90% Enjoy speed, efficiency, and faster time-to-market with our codeless, intelligent platform.
Test automation is slow and inefficient, typically requiring 8 hours to automate 2-3 tests. Manual coding slows down test creation and increases the time-to-market.
Reduces your resource burden with a codeless platform where a single team can automate everything in-sprint. Significantly minimise costs, eliminate the need for specialised engineers, and simplify your testing workflow.
Demand both specialised engineers and manual testers, driving up resource costs and requiring larger teams to manage the manual-to-automation transition.
Offers seamless CI/CD integration out-of-the-box, allowing for continuous testing and development without the need for complex scripting, simplifying your DevOps pipeline and speeding up your releases.
Are not agile and struggle with complex CI/CD integration, often needing custom scripts to function effectively within continuous delivery environments. This adds technical complexity to the process.
Provides distributed execution with flexible cloud deployment, ensuring that you can easily adapt to new technologies and scale effortlessly, without the need for manual reconfiguration.
Lag behind when adapting to evolving technologies, requiring constant manual updates to testing frameworks. Cloud and distributed execution setups are challenging to implement efficiently.
The AI-powered test data management and synthetic test data generation keep your testing accurate and compliant. Ensure high-quality, tests with ‘fit for purpose’ test data that to test all possible combinations for maximum coverage!
Rely heavily on manual test data management, increasing operational overhead, and risking outdated or inaccurate test data. This approach can be cumbersome and error-prone.
Frequently Asked Questions
What are the advantages of using Synthetic Test Data for testing?
Synthetic data’s biggest benefit is that it eliminates the risk of exposing critical sensitive information to non-production environments. In the opposite case where real data is used, even if it is protected by encryption, anonymization, or other advanced privacy preserving techniques, there is always the risk of compromising or exposing it in some way.
It also allows the creation of diverse and complex testing scenarios that might not be possible with limited real data, enabling more comprehensive testing for different scenarios, including edge cases.
Using synthetic test data reduces the need for large-scale storage and management of actual customer data for testing, thereby cutting down infrastructure and operational costs.
Why is model-driven test automation better than traditional test automation?
Model-driven test automation improves efficiency by using visual models to represent business processes, making test creation and maintenance easier. Test modeling is more about high-level test design than low-level test coding. Unlike traditional scripting methods, it reduces the manual effort, minimizes errors, and enhances reusability across your testing assets.
A key advantage is that the data is automatically updated after each change in the application model, ensuring that your tests remain accurate and always up-to-date. This approach also provides better test coverage, faster execution, and easier adaptation to system changes.
It eliminates the additional costs for automation script maintenance which are a resource-intensive
and expensive activity every time an application undergoes a change. Clients can now adopt test automation as a strategic and long-term solution and benefit from lower costs and faster time to market.
What are the benefits of composable test automation?
Composable test automation allows teams to build tests using reusable building blocks, making test creation faster and more flexible. This approach improves efficiency by reducing duplication, simplifying maintenance, and enabling rapid adjustments when applications change. It also enhances collaboration between teams, as non-technical users can contribute to test design. With composable test automation, organizations achieve better scalability, faster test execution, and improved test coverage, leading to higher software quality with less effort.
How does Validata Sense.ai enhance defect prediction and analysis?
Validata sense.ai leverages AI and advanced machine learning algorithms to fully automate defect prediction and analysis. It predicts defects in real-time, identifies their root causes more rapidly, and provides AI-generated recommendations for the ‘next best actions’ to address these issues. This proactive approach enables development teams to reduce development costs and minimize project impact by addressing potential defects before they escalate.

